
Veritabanlarında İndeksler ve Arama Yöntemleri
Veritabanlarında veri arama işlemlerinin hızını artırmak için kullanılan indeks yapıları, verilerin sıralanmasını ve erişimini oldukça kolaylaştırır. Ancak, indekslerin yanlış kullanımı, sistemin performansını olumsuz etkileyebilir. Bu yazıda, indekslerin nasıl çalıştığını, farklı indeks türlerini, avantajlarını ve dezavantajlarını ele alacağız.
İndeks Nedir?
İndeks, veritabanındaki veri tablosunda hızlı arama yapabilmek için kullanılan veri yapılarıdır. Aynen kitapların arkasındaki konu indeksleri gibi, veritabanlarındaki verilerin hızlıca erişilmesini sağlar. İndeksler, veritabanı tablolarındaki belirli sütunlara göre düzenlenir ve verinin arama, sıralama ve filtreleme işlemlerini hızlandırır.
İndeks Türleri
Veritabanlarında yaygın olarak kullanılan üç temel indeks türü vardır:
1. Clustered Index (Kümelenmiş İndeks)
- Veriyi fiziksel olarak sıralar.
- Her tabloda yalnızca bir tane clustered index olabilir.
- Primary Key genellikle clustered index olarak kullanılır.
- Verilerin sıralı bir şekilde düzenlenmesini sağlar.
2. Non-Clustered Index (Kümelenmemiş İndeks)
- Veriyi sıralamaz, sadece verinin yerini gösteren bir adres tablosu oluşturur.
- Bir tabloda birden fazla non-clustered index olabilir.
- İndeks yapısı genellikle arka planda ayrı bir veri yapısı olarak tutulur.
3. Unique Index (Benzersiz İndeks)
- Bu tür indeksler, belirli bir sütun üzerinde benzersiz verilerin olmasını garanti eder.
- Örneğin, bir name alanında aynı değerin birden fazla kez girilmesini engeller.
Arama Yöntemleri
Veritabanlarında veri arama işlemleri için genellikle iki temel yöntem kullanılır:
1. Binary Search (İkili Arama)
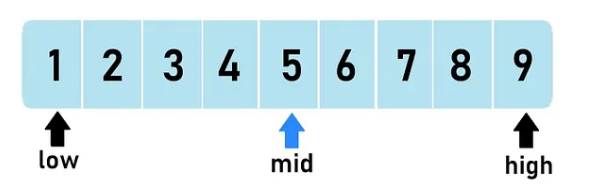
İkili arama, sıralı verilere yönelik çok verimli bir algoritmadır. İkili arama ile bir veriye ulaşmak için veri kümesini her adımda ikiye bölersiniz. Örneğin, elimizde 1000 satırlık sıralı bir liste olduğunu düşünelim:
- İlk adımda listeyi ortadan ikiye böleriz (500'e kadar olanlar ve 500'den sonrası).
- Diyelim ki, aradığımız kişi Ömer Erbaş ve bu ismin baş harfi “Ö”, “İ” harflerinden büyük olduğu için ilk 500 satır elenir.
- İkinci adımda, geriye kalan 500 satırdan 750'ye gelirsiniz. Burada, Riza’nın harfi “R” olduğu için 750'den önceki kısmı elersiniz.
- Bu şekilde her adımda verileri yarıya indirerek hedef veriye ulaşmak mümkündür.
Bu örnekte 9 adımda hedef veriye ulaşmış olduk.
2. Table Scan (Tablo Tarama)
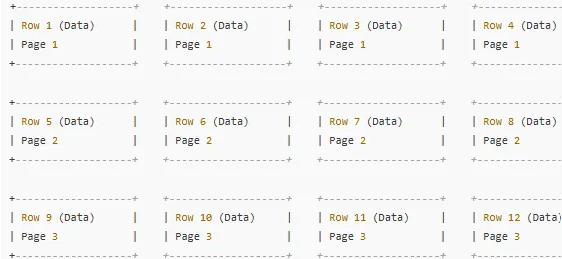
Table Scan, veritabanı tablosunda veri ararken tam bir tarama yapılmasını ifade eder. Bu yöntemde veriler sırasız bir şekilde kontrol edilir. Her page (sayfa) 8 KB’lık küçük bir veri blokudur ve veritabanı sırasız bir şekilde sayfalarda veri arar. Bu yöntem, sıralı indeks kullanmadığınızda en verimsiz arama şeklidir ve genellikle primary key olmayan veya indekslenmemiş alanlarda kullanılır.
İndekslerin Çalışma Yöntemleri
Clustered index ve non-clustered index arasındaki farkları daha net anlayalım:
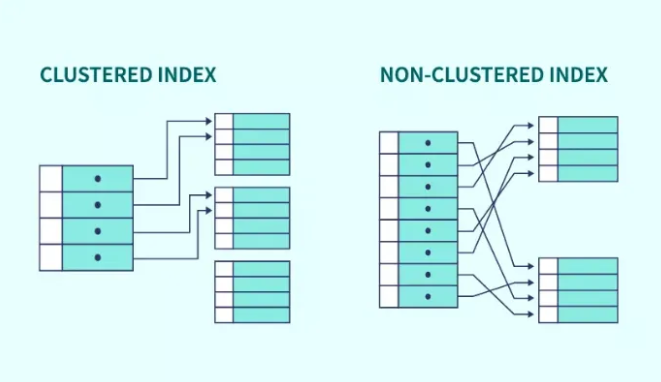
- Clustered Index: Bu indeks türü, verilerin fiziksel olarak sıralı bir şekilde disk üzerinde düzenlenmesini sağlar. Tabloyu sıralı bir biçimde depolayarak arama işlemlerinin hızlanmasını sağlar. Ancak, sadece bir tane clustered index olabilir.
- Non-Clustered Index: Bu indeks, verileri sıralamak yerine sadece verilerin yerini gösteren bir işaretçi sağlar. Non-clustered indeks, genellikle ayrı bir veri yapısında tutulur ve bir tablodaki birden fazla non-clustered index olabilir.
İndeks Bozulmaları ve Performans Sorunları
Veritabanlarında indeksler, genellikle 8 KB’lık sayfalar (pages) halinde saklanır. Ancak, veri eklemeleri yapıldıkça bu sayfalar dağınık bir şekilde oluşturulabilir. İndeks bozulması (fragmentasyonu) genellikle bu tür eklemeler sırasında ortaya çıkar. Yeni veriler çoğunlukla son sayfaya eklenir, ancak indeks bozulursa, veriler düzgün bir şekilde sıralanamaz ve indeksin yeniden düzenlenmesi gerekir. Bu tür yeniden düzenleme işlemleri oldukça maliyetli olabilir ve veritabanı performansını olumsuz etkileyebilir.
Fill Factor (Doluluk Oranı)
İndeksin nasıl düzenlendiğini ve veri eklemelerinin nasıl yapıldığını belirleyen önemli bir parametre Fill Factor (Doluluk Oranı)’dır. Fill Factor, indeks sayfalarının ne kadarının dolacağını ve ne kadar boş alan bırakılacağını belirler.
- Yüksek Fill Factor: Eğer Fill Factor değeri yüksek belirlenirse, sayfalar daha dolu olur ve yeni veriler eklenirken mevcut sayfalar üzerinde daha fazla düzenleme yapılması gerekir. Bu, özellikle sık veri eklemeleri yapıldığında indeksin bozulma oranını artırabilir ve indeksin yeniden düzenlenmesi gerektiğinde yüksek maliyetlere yol açabilir.
- Düşük Fill Factor: Düşük bir Fill Factor değeri, indeks sayfalarında daha fazla boşluk bırakır. Bu, verilerin yeni sayfalara eklenmesi yerine mevcut sayfalara eklenmesini sağlar. Bu şekilde indeksin daha hızlı büyümesi sağlanabilir, ancak fazla boşluk bırakılması indeksin daha fazla disk alanı kullanmasına neden olabilir.
İndeks Bozulması genellikle veritabanında yapılan ekleme, güncelleme veya silme işlemleri sırasında meydana gelir. İndeksin fiziksel yapısı bozulduğunda, veritabanı sorgularının çalışması yavaşlayabilir ve performans düşüşü gözlemlenebilir. Bu nedenle, veritabanı yöneticileri düzenli olarak indeks bakım işlemleri yapmalı ve fragmentasyonu önlemek için rebuild veya reorganize gibi işlemleri kullanmalıdır.
Rebuild ve Reorganize İndeksleri
- Rebuild:İndeksin tamamen yeniden oluşturulmasını sağlar. Fiziksel yapısı sıfırlanır ve indeks sıralı bir şekilde yeniden oluşturulur. Bu işlem, indeksin yüksek oranda bozulduğu veya büyük bir fragmentasyona uğradığı durumlarda kullanılır. İndeksin tüm sayfaları yeniden sıralanır ve bu da performansı artırır.
- Reorganize: Bu işlem ise indeksin yapısını bozmaz, sadece küçük parçalanmalar giderilir ve daha az maliyetlidir. Online olarak yapılabilir, yani veritabanı çalışmaya devam ederken uygulanabilir.
Ne Zaman Kullanılır?
- Rebuild: İndeksin %30 veya daha fazla fragmentasyona uğramış olduğu durumlarda kullanılır. Bu durumda, yüksek performanslı sorgulara ihtiyaç duyuluyorsa rebuild tercih edilir.
- Reorganize: İndeksin küçük oranda bozulduğu ve performans kayıplarının minimal olduğu durumlarda kullanılır.
Partitioning (Bölme)
Partitioning, büyük veritabanlarını yönetilebilir parçalara ayırmak için kullanılan bir tekniktir. Veritabanındaki veri, mantıklı bir şekilde bölümlere (partitions) ayrılır ve her bölümün indeksleri ayrı ayrı oluşturulur. Bu, indeks bozulmalarını azaltabilir çünkü her bölümde yapılan veri işlemleri, diğer bölümleri etkilemeden yapılır.
Ne Zaman Kullanılır?
Büyük boyutlu veritabanlarında veya veri kümesinin sık sık güncellendiği durumlarda partitioning uygulanabilir. Örneğin, bir satış verisi tablosu yıllık olarak ayrılabilir, böylece her yıl için ayrı bir bölüm oluşturulabilir. Bu şekilde her bir bölüme yapılan işlemler, yalnızca o bölümdeki indeks yapısını etkiler ve bozulmaların önüne geçilir.
İndeks Kolonlarını Optimize Etmek
İndeksler, sıklıkla sorgulanan sütunlar üzerinde oluşturulmalıdır. İndeks kolonlarının küçük, kısa ve veri türü açısından optimize edilmesi performans açısından önemlidir.
Ne Zaman Kullanılır?
Eğer veritabanında çok fazla büyük metin veya blob verisi varsa, bu tür veriler indeksleme işlemini ağırlaştırabilir. Bu yüzden, indeks kolonları küçük, sık kullanılan ve sorgularda yer alan alanlar olmalıdır.
Page Size Ayarları
Page Size ayarı, indekslerin fiziksel olarak ne kadar alanda saklanacağına karar verir. Veritabanlarında page size genellikle 8 KB olarak belirlenmiştir, ancak veritabanı sistemine ve iş yüküne bağlı olarak bu ayar optimize edilebilir.
Ne Zaman Kullanılır?
Çok büyük veritabanları veya indeks yapıları için page size artırılabilir. Bu, verilerin daha az sayfada depolanmasını sağlayarak, bozulma oranını azaltabilir. Ancak çok büyük page boyutları da bellek kullanımını artırabilir, bu yüzden dengeli bir seçim yapılmalıdır.
Veri Ekleme Stratejileri
Veritabanına yeni veri eklerken, verilerin nasıl ekleneceği de indeks bozulmasını etkileyebilir. Eğer veriler düzensiz bir şekilde eklenirse, indeksler daha fazla bozulur. Bu nedenle veri ekleme işlemleri toplu (batch) şekilde yapılmalıdır.
Ne Zaman Kullanılır?
Eğer çok sık veri eklenmesi gereken bir sistemde çalışıyorsanız, batch işlemler yaparak her eklemeden sonra indekslerin bozulmasını engelleyebilirsiniz.
İndeks Sayfası Bozulmalarını İzlemek
İndekslerdeki bozulma oranlarını düzenli olarak izlemek önemlidir. SQL Server gibi veritabanı yönetim sistemlerinde, DMV (Dynamic Management Views) kullanarak indekslerin durumu izlenebilir.
İndekslerin Düzenli Bakımı
İndekslerin periyodik bakımını yapmak, bozulmaların önüne geçilmesinde önemli bir adımdır. SQL Server ve diğer veritabanı sistemlerinde, maintenance plans ile otomatik bakım işlemleri oluşturulabilir.
İndekslerin Avantajları ve Dezavantajları
Avantajlar:
- Hızlı arama ve veri erişimi
- Veri bütünlüğü sağlama (özellikle unique index ile)
- Veritabanı performansının iyileştirilmesi
Dezavantajlar:
- Disk alanı tüketimi
- CRUD işlemlerinde yavaşlama
- İndeks bozulmalarının yönetilmesi gerekebilir
SONUÇ
Veritabanlarında indeksler, veriye hızlı erişim sağlamak için oldukça önemlidir. Ancak, indekslerin yanlış kullanımı, fazla yer kaplamalarına ve sistemin yavaşlamasına neden olabilir. Clustered ve non-clustered indekslerin doğru bir şekilde seçilmesi ve index bozulmalarının engellenmesi, veritabanı performansını önemli ölçüde iyileştirebilir. Bu yüzden, indeksleri doğru yönetmek ve sadece gerekli alanlarda kullanmak çok önemlidir.
İşte mülakatta indeksler ve veritabanı performansı ile ilgili sorulabilecek soruların bir listesi:
İndeks Temel Kavramları ve Çalışma Prensipleri
- İndeks nedir? Veritabanlarında nasıl çalışır ve hangi problemlere çözüm getirir?
- Clustered ve non-clustered indeks arasındaki farkları açıklayın.
- Unique index nedir? Hangi durumlarda kullanılır?
- Bir veritabanı tablosunda aynı anda kaç tane clustered index olabilir?
- Non-clustered indeksin nasıl çalıştığını ve hangi durumlarda kullanıldığını anlatın.
Arama Yöntemleri ve Performans
- Binary search (ikili arama) nedir ve nasıl çalışır? Bir örnekle açıklayınız./li>
- Table scan nedir ve hangi durumlarda kullanılır?
- Clustered ve non-clustered indeks kullanılarak yapılan arama işlemleri arasındaki farklar nelerdir?
- Bir veritabanı sorgusunda ikili arama nasıl performansı artırır?
İndeks Bozulması ve Performans Sorunları
- İndeks bozulması (fragmentasyon) nedir ve nasıl oluşur?
- Veritabanında indeks bozulmasını nasıl tespit edersiniz?
- Fill factor (doluluk oranı) nedir ve indeksin performansı üzerinde nasıl bir etkisi vardır?
- Yüksek Fill factor ile düşük Fill factor arasındaki farkları açıklayın. Hangi durumlarda hangi değer kullanılmalıdır?
- İndeks bozulması (fragmentasyon) performans üzerinde nasıl bir etkisi yaratır?
- İndeks bozulmasını (fragmentasyon) önlemek için neler yapılabilir?
- Rebuild ve Reorganize işlemleri arasındaki farkları açıklayın ve ne zaman kullanılır?
- Veritabanı yönetim sistemlerinde indeks bakımının önemi nedir?
- İndekslerin düzenli bakımı yapılmazsa ne tür performans sorunları ortaya çıkabilir?
- Veritabanına veri eklerken, indeksin bozulmasını azaltmak için hangi stratejiler izlenmelidir?
Yorumlar